
音视频基础知识、YUV、H264
一、音视频学习路径二、音视频播放原理直观应用上,音视频播放主要分为两大类:在线播放和本地播放。在线播放即通过互联网,在线播放音视频;本地播放及播放本地存放的音视频文件。这样讲应该比较好理解吧。回到开头引出的问题,音视频播放的原理主要分为:解协议->解封装->解码->音视频同步->播放。当然,如果是本地播放,没有解协议这一步骤。解协议是指从bit流中分析http、rtmp等协
一、音视频学习路径

二、音视频播放原理
视频是利用人眼视觉暂留的原理,通过播放一系列的图片,使人眼产生运动的感觉。单纯传输视频画面,视频量非常大,对现有的网络和存储来说是不可接受的。为了能够使视频便于传输和存储,人们发现视频有大量重复的信息,如果将重复信息在发送端去掉,在接收端恢复出来,这样就大大减少了视频数据的文件,因此有了H.264视频压缩标准。
视频里边的原始图像数据会采用 H.264编码格式进行压缩,音频采样数据会采用 AAC 编码格式进行压缩。视频内容经过编码压缩后,确实有利于存储和传输。不过当要观看播放时,相应地也需要解码过程。因此编码和解码之间,显然需要约定一种编码器和解码器都可以理解的约定。就视频图像编码和解码而言,这种约定很简单:
编码器将多张图像进行编码后生产成一段一段的 GOP ( Group of Pictures ) , 解码器在播放时则是读取一段一段的 GOP 进行解码后读取画面再渲染显示。GOP ( Group of Pictures) 是一组连续的画面,由一张 I 帧和数张 B / P 帧组成,是视频图像编码器和解码器存取的基本单位,它的排列顺序将会一直重复到影像结束。I 帧是内部编码帧(也称为关键帧),P帧是前向预测帧(前向参考帧),B 帧是双向内插帧(双向参考帧)。简单地讲,I 帧是一个完整的画面,而 P 帧和 B 帧记录的是相对于 I 帧的变化。如果没有 I 帧,P 帧和 B 帧就无法解码。
在H.264压缩标准中I帧、P帧、B帧用于表示传输的视频画面。

直观应用上,音视频播放主要分为两大类:在线播放和本地播放。在线播放即通过互联网,在线播放音视频;本地播放及播放本地存放的音视频文件。这样讲应该比较好理解吧。
音视频播放的原理主要分为:解协议->解封装->解码->音视频同步->播放。当然,如果是本地播放,没有解协议这一步骤。
解协议是指从bit流中分析http、rtmp等协议。
封装格式的主要作用是把视频码流和音频码流按照一定的格式存储在一个文件中。解封装就是从bit流分离出音视频。
音视频播放的原理如下(大家可以想象成剥洋葱一样,音视频播放其实是一层层的去除协议、封装,再解码,最后得到原始数据):

概念区分
录播:录播更侧重于“录”,比如录播系统,主要集成了音视频的采集、后期剪辑、工具软件的系统。通俗的讲录播就是生产音视频。
点播:点播从字面意义上讲是播放选择的视频,比如观看爱奇艺、腾讯等视频网站的电影和综艺,可以随意拖动视频进度,这些音视频共性特点是提前录制好的。通俗的讲点播就是播放录制好的视频,点播是消费音视频。
直播:直播相对好理解,虎牙、斗鱼等直播平台上的游戏、才艺直播,这些音视频共性特点是实时的,观看者不能拖动音视频进度。通俗的讲直播就是播放实时直播视频,直播既生产又消费音视频。
三、视频编码前的图像格式
首先要说明RGB、YUV和YCbCr都是人为规定的彩色模型或颜色空间(有时也叫彩色系统或彩色空间)。它的用途是在某些标准下用通常可接受的方式对彩色加以描述。YUV是音视频(编解码)最常用的格式。
【1】RGB
RGB(红绿蓝)是依据人眼识别的颜色定义出的空间,可表示大部分颜色。但在科学研究一般不采用RGB颜色空间,因为它的细节难以进行数字化的调整。它将色调,亮度,饱和度三个量放在一起表示,很难分开。它是最通用的面向硬件的彩色模型。该模型用于彩色监视器和一大类彩色视频摄像。
【2】YUV
在 YUV空间中,每一个颜色有一个亮度信号 Y,和两个色度信号 U 和V。亮度信号是强度的感觉,它和色度信号断开,这样的话强度就可以在不影响颜色的情况下改变。
YUV使用RGB的信息,但它从全彩色图像中产生一个黑白图像,然后提取出三个主要的颜色变成两个额外的信号来描述颜色。把这三个信号组合回来就可以产生一个全彩色图像。
【3】YCbCr
YCbCr 是在世界数字组织视频标准研制过程中作为ITU - R BT1601 建议的一部分,其实是YUV经过缩放和偏移的翻版。其中Y与YUV 中的Y含义一致, Cb , Cr 同样都指色彩, 只是在表示方法上不同而已,Cb表示蓝色分量,Cr表示红色分量。在YUV家族中, YCbCr 是在计算机系统中应用最多的成员,其应用领域很广泛,JPEG、MPEG均采用此格式。一般人们所讲的YUV大多是指YCbCr。YCbCr 有许多取样格式, 如4∶4∶4 , 4∶2∶2 , 4∶1∶1 和4∶2∶0。
下面将的YUV指YCbCr。主要的采样格式有YCbCr 4:2:0、YCbCr 4:2:2、YCbCr 4:1:1和 YCbCr 4:4:4。其中YCbCr4:1:1 比较常用,其含义为:每个像素点保存一个 8bit 的亮度值(也就是Y值), 每 2 x 2 个像素点保存一个 Cr和Cb值,此种方式表示出来的图像和RGB表示出来的图像在肉眼中的感觉不会有太大的区别。所以, 原来用 RGB(R,G,B 都是 8bit unsigned) 模型, 每个像素点需要8x3=24 bits, 而现在仅需要 8+(8/4)+(8/4)=12bits,平均每个像素点占12bits。这样就把图像的数据压缩了一半。
1.YUV的数据格式是如何呢?
YUV有两种分类方式,即“空间-间”和“空间-内”。“空间-间”的划分方式主要体现在Y、U、V的比例不同;“空间-内”的划分方式主要体现在Y、U、V的比例一定,存储格式不同。
2.YUV“空间-间”的数据划分
YUV按照“空间-间”的划分方式,分为YUV444、YUV422、YUV420。下面的计算假设图像像素为1920*1080。
下面每个 [] 表示一个像素点 。 Y、U、V每个分量占用8bit。
(1) YUV 4:4:4
YUV444,每个像素点都含有YUV,共3个字节。
YUV三个信道的抽样率相同,因此在生成的图像里,每个象素的三个分量信息完整(每个分量通常8比特),经过8比特量化之后,未经压缩的每个像素占用3个字节。
(2) YUV 4:2:2
YUV422,每两个Y共用一个uv分量。所以在1920*1080整个图像中,u、v都是只有一半的像素点含有,y每个像素都含有,u、v共占用1920*1080*0.5个字节。
对非压缩的8比特量化的图像来说,每个由两个水平方向相邻的像素组成的宏像素需要占用4字节内存(例如下面映射出的前两个像素点只需要Y、U、Y、V四个字节)。
(3)YUV4:2:0
4:2:0并不意味着只有Y,Cb而没有Cr分量。它指得是对每行扫描线来说,只有一种色度分量,Y和某色度分量以2:1的抽样率存储。相邻的扫描行存储不同的色度分量,也就是说,如果一行是4:2:0的话,下一行就是4:0:2,再下一行是4:2:0...以此类推。对每个色度分量来说,水平方向和竖直方向的抽样率都是2:1,所以可以说色度的抽样率是4:1。
对于每个Y、Cb、Cr分量用8比特量化的视频来说,每个由2x2个2行2列相邻的像素组成的宏像素需要占用6字节内存。1920x1080的图像,其中每个像素点都有Y分量,其中四分之一的像素点含有Cb分量,其中四分之一的像素点含有Cr分量,所以总共占用字节为【1920*1080*1+1920*1080*0.25+1920*1080*0.25】。



3.YUV“空间-内”的数据划分
YUV按照“空间-内”的划分方式,主要分为packet、planar、semi-planar三种:
◆ packet:打包格式,即先存储一个yuv,再存储下一个yuv;
◆ planar:平面格式,即先存储y平面,再存储u平面,再存储v平面;
◆ semi-planar:先存储y平面,再存储uv平面;
◆ YUV422各种存储格式如下:
◆ YUV420各种存储格式如下:
针对上图中的NV12、NV21、NV16、NV61说明:
◆NV:NV系列都属于semi-plane系列,“12”、“16”代表先U后V,“21”、“61”代表先V后U
◆ 12、16:代表一个像素占的位数


4.YUV和RGB转换
RGB:即red,green,blue三色存储空间,因音视频主要用的是YUV的色彩空间,感兴趣的小伙伴可以拓展下RGB相关知识,本文不再详述。介绍下RGB和YUV的转换公式:
◆ RGB 转 YUV:
Y = 0.299R + 0.587G + 0.114B
U= -0.147R - 0.289G + 0.436B
V = 0.615R - 0.515G - 0.100B
◆ YUV 转 RGB:
R = Y + 1.14V
G = Y - 0.39U - 0.58V
B = Y + 2.03U
四、H264压缩编码格式
H.264作为现在应用比较广泛的视频压缩编码格式标准,本文笔者介绍下H.264相关知识。
1.什么是H.264
H.264是由ITU-T视频编码专家组(VCEG)和ISO/IEC动态图像专家组(MPEG)联合组成的联合视频组(JVT,Joint Video Team)提出的高度压缩数字视频编解码器标准。
2.H.264的数据格式是怎样的?
H.264中,将视频数据编码后的数据称为编码层(VCL),VCL进一步封装后的数据称为网络适配层(NAL)。
◆ VCL:H264编码/压缩的核心,主要负责将视频数据编码/压缩,再切分。
◆ NALU = NALU header + NALU payload。payload就是数据。
NALU 是NAL unit简写。nal是一个统称,nal unit是一个个的数据单元。nal unit = nal header + 视频slice数据。nal层的基本单位叫NALU 。
3.VCL如何管理H264视频数据?
◆ 压缩:预测(帧内预测和帧间预测)-> DCT变化和量化 -> 比特流编码;
◆ 切分数据,主要为了第三步。"切片(slice)"、“宏块(macroblock)"是在VCL中的概念,一方面提高编码效率和降低误码率、另一方面提高网络传输的灵活性。
◆ 包装成『NAL』。
◆ 『VCL』最后会被包装成『NAL』
4.NALU头的数据结构体
◆ F(forbidden_zero_bit):1 位,初始为0。当网络识别此单元存在比特错误时,可将其设为 1,以便接收方丢掉该单元
◆ NRI(nal_ref_idc):2 位,用来指示该NALU 的重要性等级。值越大,表示当前NALU越重要。具体大于0 时取何值,没有明确规定
◆ Type(nal_unit_type):5 位,指出NALU 的类型,如下所示:


5.H.264码流结构
◆ H.264 = start_code + NALU(start_code:00000001 or 000001)
◆ 每个NAL前有一个起始码 0x00 00 01(或者0x00 00 00 01),解码器检测每个起始码,作为一个NAL的起始标识,当检测到下一个起始码时,当前NAL结束。
◆ 同时H.264规定,当检测到0x000000时,也可以表征当前NAL的结束。那么NAL中数据出现0x000001或0x000000时怎么办?H.264引入了防止竞争机制,如果编码器检测到NAL数据存在0x000001或0x000000时,编码器会在最后个字节前插入一个新的字节0x03,这样:
0x000000->0x00000300
0x000001->0x00000301

6.I帧、P帧和B帧
提到H.264,不得不提I帧、P帧、B帧、IDR帧、GOP。
◆帧:即Intra-coded picture(帧内编码图像帧),I帧表示关键帧,你可以理解为这一帧画面的完整保留;解码时只需要本帧数据就可以完成(因为包含完整画面)。又称为内部画面 (intra picture),I 帧通常是每个 GOP(MPEG 所使用的一种视频压缩技术)的第一个帧,经过适度地压缩,做为随机访问的参考点,可以当成图象。在MPEG编码的过程中,部分视频帧序列压缩成为I帧;部分压缩成P帧;还有部分压缩成B帧。I帧法是帧内压缩法,也称为“关键帧”压缩法。I帧法是基于离散余弦变换DCT(Discrete Cosine Transform)的压缩技术,这种算法与JPEG压缩算法类似。采用I帧压缩可达到1/6的压缩比而无明显的压缩痕迹。
例如:在视频会议系统中,终端发送给MCU(或者MCU发送给终端)的图像,并不是每次都把完整的一幅幅图片发送到远端,而只是发送后一幅画面在前一幅画面基础上发生变化的部分。如果在网络状况不好的情况下,终端就会有丢包而出现图像花屏、图像卡顿的现象,在这种情况下如果没有I帧机制来让远端重新发一幅新的完整的图像到本地,终端的输出图像的花屏、卡顿现象会越来越严重,从而造成会议无法正常进行。
在视频画面播放过程中,若I帧丢失了,则后面的P帧也就随着解不出来,就会出现视频画面黑屏的现象;若P帧丢失了,则视频画面会出现花屏、马赛克等现象。
◆ P帧(Predictive-coded picture,前向预测编码图像帧),表示的是跟之前的一个关键帧或P帧的差别,P帧是参考帧,它可能造成解码错误的扩散;
◆ B帧(Bidirectionally predicted picture,双向预测编码图像帧),本帧与前后帧(I或P帧)的差别,B帧压缩率高,但要解码B帧,不仅要取得之前的缓存画面,还要解码之后的画面,通过前后画面的与本帧数据的叠加取得最终的画面。B帧压缩率高,但是解码时CPU会比较累。
◆ IDR帧(Instantaneous Decoding Refresh,即时解码刷新):GOP开头的I帧,是立刻刷新,使错误不致传播,IDR导致DPB(DecodedPictureBuffer参考帧列表——这是关键所在)清空;在IDR帧之后的所有帧都不能引用任何IDR帧之前的帧的内容;IDR具有随机访问的能力,播放器可以从一个IDR帧播放。
◆ GOP(Group Of Picture,图像序列):两个I帧之间是一个图像集合,一个GOP包含一个I帧。每个GOP图像序列的开头I帧就是IDR。
【为什么需要B帧】
从上面来看,我们知道I和P的解码算法比较简单,资源占用也比较少,I只要自己完成就行了,P呢,也只需要解码器把前一个画面缓存一下,遇到P时就使用之前缓存的画面就好了,如果视频流只有I和P,解码器可以不管后面的数据,边读边解码,线性前进,大家很舒服。那么为什么还要引入B帧?
网络上的电影很多都采用了B帧,因为B帧记录的是前后帧的差别,比P帧能节约更多的空间,这是。
但这样一来,文件小了,解码器就麻烦了,因为在解码时,不仅要用之前缓存的画面,还要知道下一个I或者P的画面(也就是说要预读预解码),而且,B帧不能简单地丢掉,因为B帧其实也包含了画面信息,如果简单丢掉,并用之前的画面简单重复,就会造成画面卡(其实就是丢帧了),并且由于网络上的电影为了节约空间,往往使用相当多的B帧,B帧用的多,对不支持B帧的播放器就造成更大的困扰,画面也就越卡。
【显示和解码顺序示意图】
GOP(序列)和IDR
在视频编码序列中,GOP即Group of picture(图像组),指两个I帧之间的距离,Reference(参考周期)指两个P帧之间的距离。两个I帧之间形成一组图片,就是GOP(Group Of Picture)。
在H264中图像以GOP为单位进行组织,一个GOP是一段图像编码后的数据流。
一个GOP的第一个图像叫做 IDR 图像(立即刷新图像),IDR 图像都是 I 帧图像。H.264 引入 IDR 图像是为了解码的重同步,当解码器解码到 IDR 图像时,立即将参考帧队列清空,将已解码的数据全部输出或抛弃,重新查找参数集,开始一个新的GOP。这样,如果前一个GOP出现重大错误,在这里可以获得重新同步的机会。IDR图像之后的图像永远不会使用IDR之前的图像的数据来解码。
一个GOP就是一段内容差异不太大的图像编码后生成的一串数据流。当运动变化比较少时,一个GOP可以很长,因为运动变化少就代表图像画面的内容变动很小,所以就可以编一个I帧,然后一直P帧、B帧了。当运动变化多时,可能一个GOP就比较短了,比如就包含一个I帧和3、4个P帧。【GOP示意图】

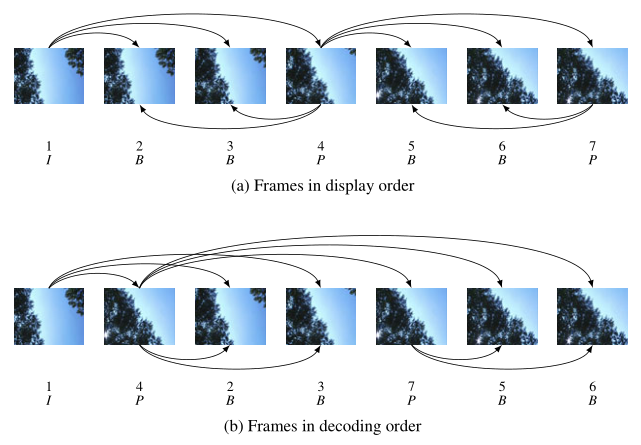

7.PTS和DTS
【为什么会有PTS和DTS的概念】
通过上面的描述可以看出:P帧需要参考前面的I帧或P帧才可以生成一张完整的图片,而B帧则需要参考前面I帧或P帧及其后面的一个P帧才可以生成一张完整的图片。这样就带来了一个问题:在视频流中,先到来的 B 帧无法立即解码,需要等待它依赖的后面的 I、P 帧先解码完成,这样一来播放时间与解码时间不一致了,顺序打乱了,那这些帧该如何播放呢?这时就引入了另外两个概念:DTS 和 PTS。
【PTS和DTS】
先来了解一下PTS和DTS的基本概念:
DTS(Decoding Time Stamp):即解码时间戳,这个时间戳的意义在于告诉播放器该在什么时候解码这一帧的数据。
PTS(Presentation Time Stamp):即显示时间戳,这个时间戳用来告诉播放器该在什么时候显示这一帧的数据。
虽然 DTS、PTS 是用于指导播放端的行为,但它们是在编码的时候由编码器生成的。
在视频采集的时候是录制一帧就编码一帧发送一帧的,在编码的时候会生成 PTS,这里需要特别注意的是 frame(帧)的编码方式,在通常的场景中,编解码器编码一个 I 帧,然后向后跳过几个帧,用编码 I 帧作为基准帧对一个未来 P 帧进行编码,然后跳回到 I 帧之后的下一个帧。编码的 I 帧和 P 帧之间的帧被编码为 B 帧。之后,编码器会再次跳过几个帧,使用第一个 P 帧作为基准帧编码另外一个 P 帧,然后再次跳回,用 B 帧填充显示序列中的空隙。这个过程不断继续,每 12 到 15 个 P 帧和 B 帧内插入一个新的 I 帧。P 帧由前一个 I 帧或 P 帧图像来预测,而 B 帧由前后的两个 P 帧或一个 I 帧和一个 P 帧来预测,因而编解码和帧的显示顺序有所不同,如下所示:
假设编码器采集到的帧是这个样子的:
I B B P B B P
那么它的显示顺序,也就是PTS应该是这样:
1 2 3 4 5 6 7
编码器的编码顺序是:
1 4 2 3 7 5 6
推流顺序也是按照编码顺序去推的,即
I P B B P B B
那么接收断收到的视频流也就是
I P B B P B B
这时候去解码,也是按照收到的视频流一帧一帧去解的了,接收一帧解码一帧,因为在编码的时候已经按照 I、B、P 的依赖关系编好了,接收到数据直接解码就好了。那么解码顺序是:
I P B B P B B DTS:1 2 3 4 5 6 7 PTS:1 4 2 3 7 5 6可以看到解码出来对应的 PTS 不是顺序的,为了正确显示视频流,这时候我们就必须按照 PTS 重新调整解码后的 frame(帧),即
I B B P B B P DTS:1 3 4 2 6 7 5 PTS:1 2 3 4 5 6 7另外,并不是一定要使用B帧。在实时互动直播系统中,很少使用B帧。主要的原因是压缩和解码B帧时,由于要双向参考,所以它需要缓冲更多的数据,且使用的CPU也会更高。由于实时性的要求,所以一般不使用它。不过对于播放器来说,遇到带有B帧的H264数据是常有的事儿。在没有B帧的情况下,存放帧的顺序和显示帧的顺序就是一样的,PTS和DTS的值也是一样的。

8.h264、h265、hevc
谈到视频的编码就不免会想到hevc、h.265、h.264这几个词。这些词也就是通常专业领域内所说的视频编码标准。随着技术的不断革新与发展,任何领域都或多或少的有一定的发展。在视频编码这个领域,也是这样。h.265也就是h.264的升级版。在前者优点的基础之上再加以改造,力求达到更优。所以出现了后者,所以在各个方面h.265在视频的压缩效率上、错误恢复上、减短时长上都有进一步的提升。hevc和h.265无区别。
参考
音视频入门系列 - 传送门

致力于链接即构和开发者,提供实时互动和元宇宙领域的前沿洞察、技术分享和丰富的开发者活动,共建实时互动世界。
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)