
实时语音视频通话SDK如何实现立体声(二)
手机只有一个麦克风,如何把单声道虚拟成立体声?在进行互动通话的时候,可不可以使用立体声?这篇文章都会聊到。
单声道虚拟成立体声
如果发送端采用外部采集,采集的设备有两个麦克风,或者本身就是立体声麦克风,那么采集进来的声音信号就是立体声的。立体声信号包含两组独立的波形,由于这两组波形有相关性,可以一起编码传输,在接收端解码以后再独立地渲染,最终获得立体声的效果。
如果发送端采用手机的唯一麦克风,采集进来的声音信号就是单声道的。如果要在接收端获得立体声的效果,就要把单声道的声音信号虚拟成立体声的。不是说巧妇难为无米之炊吗?这里也不完全是“无米”,毕竟还是有一组单声道波形数据的。
具体的做法是,首先对声音传播路径进行建模,然后输入原始的波形数据,还有距离d和角度a两个参数,模型会输出两个独立的波形,代表左右声道的声音信号。这两个波形和原始的波形作比较,在相位,音色和音调都有所调整,尽量地逼近原始波形在自然环境中传播到用户的左右耳朵后形成的两个不同的波形。这两个波形有相关性,因此一起编码后的带宽是小于每一个波形带宽的两倍。虚拟立体声信号数据到达接收端以后,结果解码就可以得到两个独立的波形声音信号数据。如果是在手机扬声器播放出来,效果还是单声道的,如果通过耳机播放出来,就能呈现出立体声的效果,用户可以听出声音的空间感,并且依此进行听声辩位。
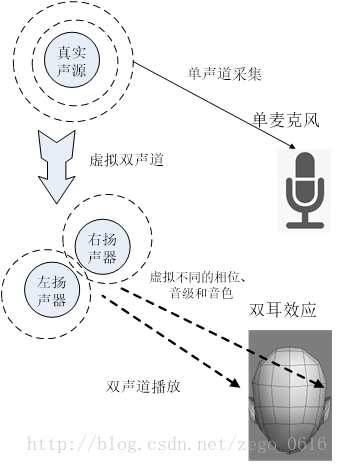
即构ZEGO把单声道虚拟成立体声,获得沉浸式听声辩位的效果
把单声道波形虚拟成两个独立的立体声波形,是在目前移动端硬件限制条件下的一个技术处理手段。虚拟立体声的处理可以在发送端进行,也可以在接收端进行。在哪里进行虚拟化,要看具体的场景需要。如果有混音的需求,也就是要把语音信号和背景音乐混合在一起的话,那么比较适合在发送端来做虚拟立体声;如果没有混音的需求,那么比较适合在接收端做虚拟立体声。背景音乐一般是立体声的,而且是在发送端输入的。如果需要进行混音,而混音必须要在发送端进行,那么背景音乐和语音信号都要是立体声才能对应得混合。因此,虚拟立体声必须要发送端完成,然后虚拟出来的语音立体声才能和背景音的立体声混合,混合好以后再把立体声信号进行编码传输,最后到了接收端解码以后就可以把立体声播放出来。如果不需要进行混音,那么可以把单声道声音信号直接编码发送,接收端收到后进行解码,再把单声道声音信号虚拟成立体声,这样传输的带宽就可以做到最低。
当互动直播遇到立体声
随着硬件的快速更新换代,在不远的将来,手机很可能会支持立体声,拥有双麦克风(考虑到手机的物理尺寸较小,笔者严重怀疑双麦克风的效果)和双扬声器。也许你会觉得这是普大喜奔的好事情,再也不用费脑去搞虚拟立体声了,然而有个现实要让你心碎:即使手机支持立体声,在进行互动直播或者互动语音视频通话的时候,手机依然只能采用单声道采集,因此,还是要继续搞虚拟立体声,这是跑不掉的事情。为什么在互动直播的时候只能采取单声道而不能采取立体声呢?下图展示了使用立体声手机进行回声消除的逻辑,大家看一下此图就理解互动直播不能采取立体声的缘由了。
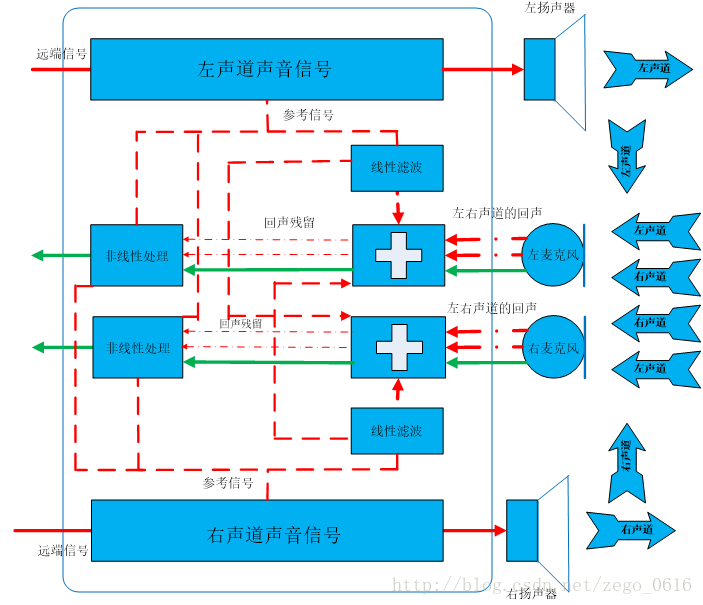
即构ZEGO:采用立体声的手机做回声消除过分复杂
参照上图,我们看一下语音数据的是如何流动的:
1)远端的左右两个麦克风分别采集左右声道的语音数据;
2)近端的左右两个扬声器分别播放左右声道的语音数据;
3)近端左边的扬声器发出的声音经过回声馈路会被近端左右的两个麦克风采集进去;
4)近端右边的扬声器和#3同理;
5)近端左边的麦克风采集进来的声音信号包括了左右两个扬声器产生的回声;
6)近端右边的麦克风和#5同理;
7)对左边麦克风采集的声音进行回声消除的时候,除了参考远端左声道声音信号消除左边扬声器产生的回声,还要参考远端右声道声音信号消除右边扬声器产生的回声;
8)对右边的麦克风采集的声音进行回声消除和#7同理。
也就是说,对左边麦克风采集进来的声音要消除左右两个扬声器产生的回声,对右边麦克风采集进来的声音进行回声消除也同理,总共要进行四次回声消除,并且要从每一个麦克风采集进来的声音信号里消除两个扬声器造成的回声,计算量一下子变成单声道情形的四倍,复杂度更是远超四倍。同等条件下,立体声回声消除的效果比起单声道回声消除的效果差。目前业界的实践表明,立体声回声消除的效果并不理想。因此,在涉及到互动直播或者互动语音视频实时通话的场景,还是要使用单声道采集和渲染比较能简单而且能保障效果。
结语
听声辩位是人们在自然环境中习以为常的事情,语音视频实时通信的愿景就是要在互联网上完美地还原自然环境的通话场景,这也是即构ZEGO孜孜不倦地追求的使命。随着AR/VR的发展,沉浸式的语音和视频消费方式成为常态,在进行语音视频实时通话的时候,人们也会要求能够做到听声辩位,在游戏语音、语音社交、视频社交、视频会议和在线教育等场景,会有广泛的需求和应用。
<本篇完>

致力于链接即构和开发者,提供实时互动和元宇宙领域的前沿洞察、技术分享和丰富的开发者活动,共建实时互动世界。
更多推荐



 0
0 0
0- 0



 已为社区贡献257条内容
已为社区贡献257条内容

所有评论(0)