
活动回顾:音视频低时延应用的技术实践(下)
8月24-25日,由LiveVideoStackCon主办的音视频技术大会在北京召开。在解决方案专场,即构科技互联网业务部技术总监邱国钦(Randy)发表了《音视频低时延应用的技术实践》的主题演讲。他首先从整体上分析了延迟是怎么构成的?有哪些关键点需要特别关注?基于对延迟的整体认识,分享低延迟的应用及技术实践。现场座无虚席,慕名而来的观众在演讲后与Randy老师进行了多轮互动,...
8月24-25日,由LiveVideoStackCon主办的音视频技术大会在北京召开。在解决方案专场,即构科技互联网业务部技术总监邱国钦(Randy)发表了《音视频低时延应用的技术实践》的主题演讲。他首先从整体上分析了延迟是怎么构成的?有哪些关键点需要特别关注?基于对延迟的整体认识,分享低延迟的应用及技术实践。

现场座无虚席,慕名而来的观众在演讲后与Randy老师进行了多轮互动,以下是活动现场的演讲实录,这是下篇内容,主要介绍低延时的应用及技术实践,以及摘录部分观众的互动提问内容:
- 低延迟的应用及技术实践
我们对低延时的应用有一个很明显的特征:强互动。互动形式有很多,第一种是双向流媒体,如通话场景;第二种是单向流媒体,一路流出去,通过信令通道做反馈互动,第三种也是单向流媒体,但流媒体内容是受控的。
要实现低延迟的应用,我们有两种思路:第一种是我们的实现要尽量低时延,不管是从架构设计,还是工程实现,尽量往物理极限逼近;第二种是结合业务场景去看哪些是可以通过策略优化来降低用户对延迟的感知。
1)直播
首先来看一个大家很熟悉的场景:直播。直播最开始的时候全走CDN,CND延迟很高,直播走CND不是很匹配,因为直播里面有一个很关键的互动叫打赏,如果一个金主打赏了礼物,主播隔了好几秒才说谢谢,会影响他送礼物的体验,从而影响平台营收。
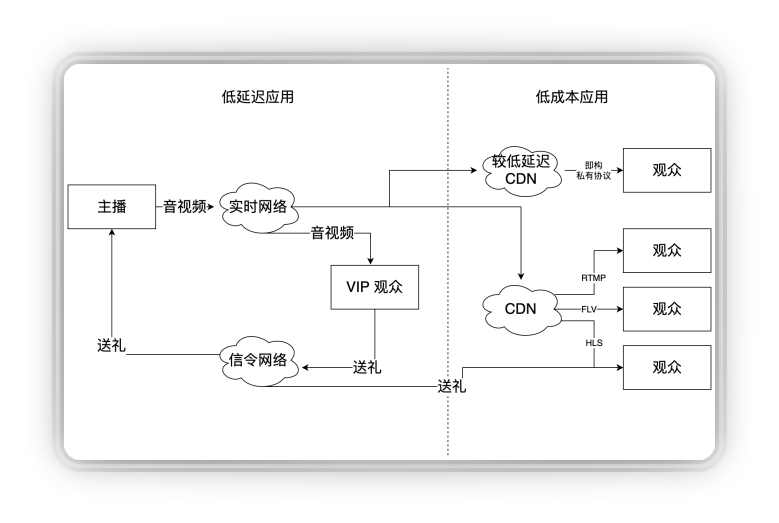
即使是在秀场直播中,也是非常需要低时延的。低时延意味着高成本,如果全走CDN,打赏的钱可能还不够支付成本。即构的方案是做切割,通过业务数据的积累,我们预判让经常参与打赏的用户走低时延,而大部分观众走CDN分发,这样既不影响“金主”的打赏体验,又让其他用户也能参与互动。
2)娃娃机
第二个应用是线上娃娃机。玩家通过信令通道给娃娃机发指令,控制娃娃机的上位机,飞车、移动、抓。同时我们在娃娃机旁边放个摄像头,去推流,推流之后通过实时网络反馈给玩家。娃娃机对时延要求很关键的地方在于,玩家是在玩游戏,你要给他一个低延迟的互动,否则他无法做响应做下一步的动作。
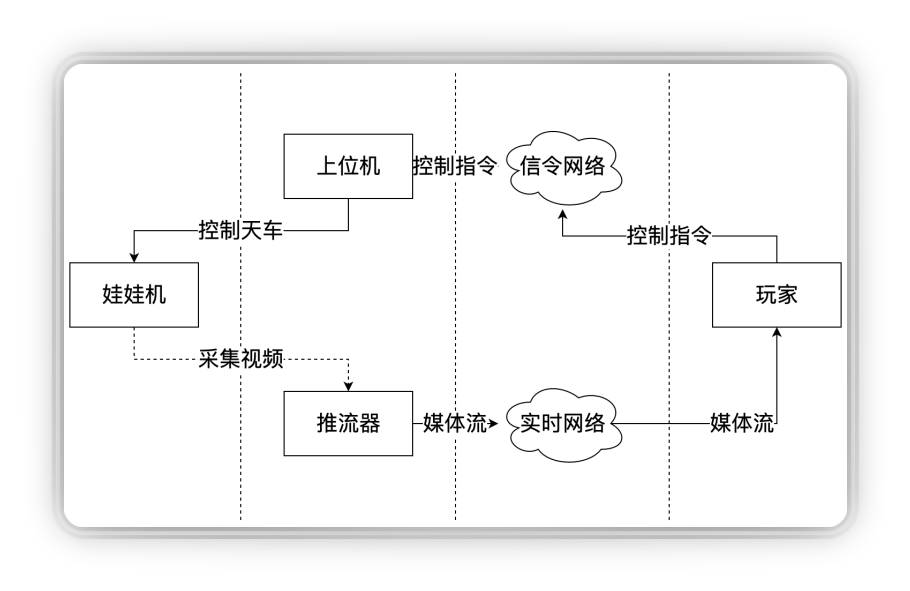
即构的方案是这样的:首先我们基于线上娃娃机的特点做了一个特殊的优化,娃娃机这端我们通过定制设备让采集的时延很低;第二娃娃机不需要美颜,前处理的时延去掉;第三娃娃机不需要音频,这是关键的地方,我们可以看到整个链路音频引入的时延是非常大的,包括采集的时延、编解码时延、音画同步的时延、渲染的时延等等,把音频去掉,这个优化就非常明显了,相比有音频时的延时可以低70-80ms。
尽管娃娃机的风口已过,但是这个方案在一些类似的场景中还是非常有参考价值,比如远程挖掘机、远程医疗、串流游戏等等。
3)AI教学
这是即构在去年年底发布的方案“AI教学”,我们把视频点播做到了实时互动。在AI教学模式中,老师根据教研设计,预测学生可能出现的反应,录制好各种对应的视频,比如在某个时间段老师会向学生提问,学生答对答错老师会有不同反应,老师提前把这些不同的反应录下来。
其实老师的每段视频都是点播,但我们把每段视频进行无缝衔接,看起来就像老师和学生在实时互动一样。我们都知道在线教育行业老师的成本是非常高的,而录播的话一次录制可以重复使用,所以这个方案目前即构的很多客户在用。
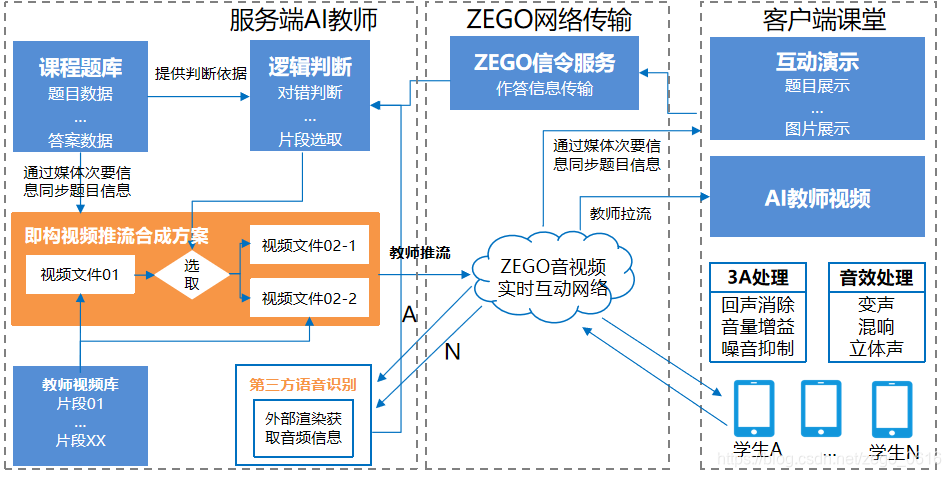
这个方案的技术难点在于,如何把多个视频文件做到快速的切换。即构提供的技术方案就包括如何通过预处理、解推码流等多步骤来实现。分享一个细节:录制的时候很难保证老师的位置固定不动,基于这种拼接需求,我们做了一个工具来实现最后一帧和第一帧的融合,来降低用户对视频拼接卡顿的感知。
感性兴趣的朋友可以点击下面的链接查看详细内容:
4)在线KTV
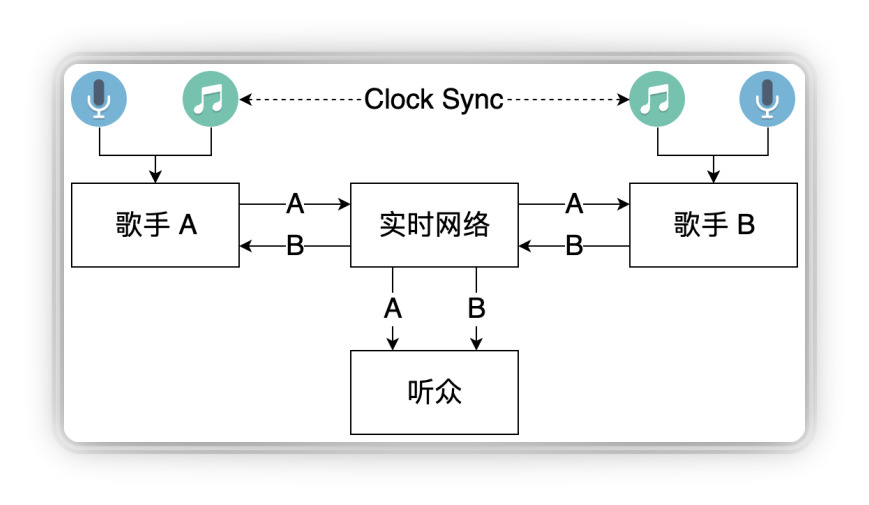
最后一个是KTV场景。我们要让歌手互动,同时要把合唱歌声推给观众。最开始即构的实现方式是:
让歌手A跟随本地伴奏唱歌,然后把歌手和伴奏合成一路推给歌手B,听到歌手A的声音后歌手B把自己的声音加进去合唱,把合唱的声音推给观众,同时歌手B把自己的声音单独推给歌手A,让A能听到B的声音。
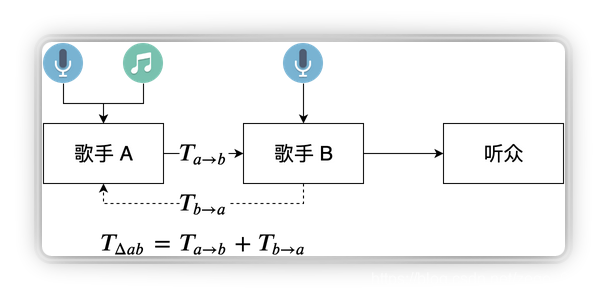
这个方案的优点在于,由于是在歌手B的本端做混音,所以不论歌手A到歌手B的时延有多高,观众听到的都是一个合拍的合唱;而缺点就是歌手A和歌手B有环回时延,双方的互动延迟是很难让用户接受的。
在这个基础上,即构做了优化的并行方案:
歌手A和歌手B都在本地播放伴奏各自随着伴奏唱歌,通过即构实时网络互发,这样它的时延就只有原来的一半,在网络较好的情况下我们可以做到单向 100ms 以内的延迟。
这里需要解决的问题是:如何让A和B同时开始唱?在分布式网络“时钟同步”是难点问题,手机没有特别的硬件,在网络抖动的情况下去做同步是很难实现的。我们需要一个基准时钟,一个可比较的时钟,那如何获取呢?
这里有一个很巧妙的方式:将歌曲的进度作为时钟。对方和我方播的是同一首歌曲,那播到了哪一毫秒,这个时间戳是可以比较的。
以B的视角来看这个问题:在Tb0这个点播放伴奏,在Tb2B听到了A的声音,知道A播放到了时间戳Ta0,我们可以通过别的方式估算出端到端的时延Ta-b,B就知道自己提前了T0时间去播放,那我们需要做的就是把T0时间消除掉。
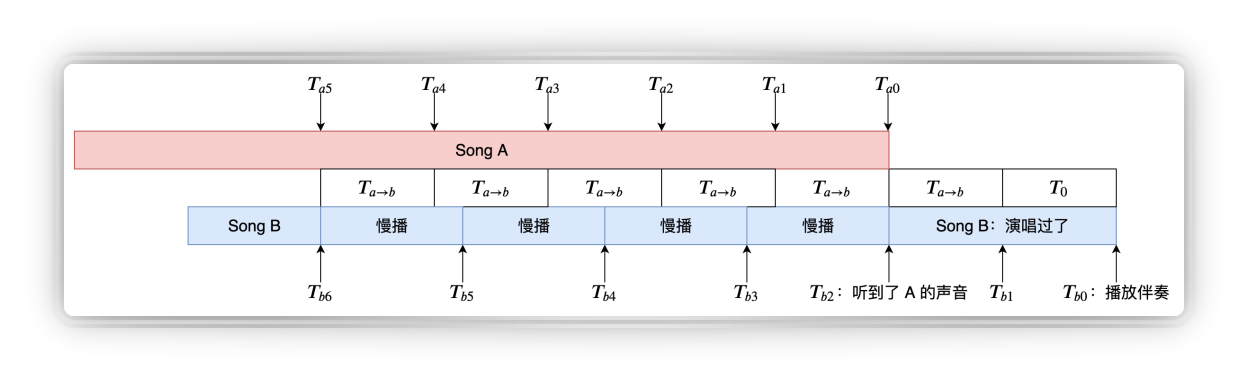
这里的策略是在播放的时候加入伸缩,伸缩在直播场景中广泛应用:在接收数据时,当突然涌进很多数据时,我们会加速播放,否则时延一直会变的很大;当Buffer少了,还要能流畅播放,那我们会加一点点拉伸。因此我们把伸缩应用在这里,给伴奏做一个拉伸,对于抢先唱的人做一个拉伸,估算出拉伸多少合适,经过几个播放后我们就能把时间戳同步到整个方案的单向时延。
以上所分享的方法主要围绕着两个方向:
- 我们需要让自己的方案在个角度各方向都尽可能低时延;
- 我们怎么从业务场景出发规避低时延带来的影响。
低延迟的实现离不开客户端、服务端、业务等各个环节的努力:更优的Codec;更好的网络设施;更好的传输协议(更底层的优化);更深入应用场景去打磨细节,与业务方深入沟通,让客户的诉求可以通过更多的方式来实现。
基于Randy老师的演讲,现场观众对即构的方案产生了浓厚的兴趣,现场提问不断,以下简单摘录了几个进行分享:
提问1:我对即构科技已经关注很久了,你们经常分享的一些方案写的都挺好的。刚才您的PPT里提到了WebRTC与你们自己协议的对比,想问下你们在设计自己的私有协议时有参考WebRTC的相关机制吗?
答:即构的私有协议是独立自研的,我们不会说故意去参考WebRTC。像FEC这个是编码里的东西而不是WebRTC固有的,特别是传输策略,我们根据我们对网络的建模,设计针对各种现实应用场景的传输策略,并在实际运营中积累数据,优化我们的传输方案。实际上我们的方案在丢包、网络抖动的情况下,效果比WebRTC更好。
提问2:在您刚才的演讲中提到了低延迟分发,我想问下在直播场景中延迟大概多少,并发数有没限制,成本的话比普通CDN分发大概高多少?
答:延迟的数据我可以告诉您,成本的数据可以联系我们的商务了解。关于并发,即构的架构是转控分离的,我们是可以做到平行扩容,所以容量与部署更相关,看客户的成本需求,需要铺多少机器,我们的架构对容量没有太多限制。关于时延的话,我们称之为较低时延,基本上可以做到1S以内。
提问3:如果只考虑传输网络,即构全球能做到多大的RTT?
答:即构的全球客户分布较多的地区有美东、美西、欧洲、东南亚、中东、非洲,我们发现跨国的传输延迟和当地的经济发展程度关系很大,从美西到国内单向延迟100多毫秒,RTT200多毫秒。
以上就是LiveVideoStackCon音视频技术大会北京站即构的分享内容,如果有更多想了解的内容,欢迎给我们留言。

致力于链接即构和开发者,提供实时互动和元宇宙领域的前沿洞察、技术分享和丰富的开发者活动,共建实时互动世界。
更多推荐



 1
1 0
0- 0



 已为社区贡献257条内容
已为社区贡献257条内容

所有评论(0)